
AML Data Quality: The Challenge of Fitting a Square Peg into a Round Hole
As mentioned in my previous articles, traditional rule-based transaction monitoring systems (TMS) have architectural limitations which make them prone to false positives and false negatives:
- Naive rules create a plague of false positives that are expensive for investigators to sift through
- Sophisticated money launderers know how to circumvent rule-based systems leading to false negatives and potential fines from regulators
This article focuses on the third drawback of existing TMS solutions: how their inflexible data models lead to poor data quality, resulting in additional false positives and false negatives.
I think many of us working in the anti-money laundering (AML) technology space have experienced the frustration of spending many hours retrofitting new data types to squeeze into the rigid data model of a TMS. Unfortunately, the more effort we spend retrofitting data, the more likely we introduce data quality issues. Further, when we don’t complete it in a timely fashion, we’re exposed to risk of large fines from regulators. That said, there’s hope on the horizon from machine learning solutions that are more forgiving of disparate data formats.
Editor's Note: This article originally appeared on the DataVisor blog on February 12, 2017.
As mentioned in my previous articles, traditional rule-based transaction monitoring systems (TMS) have architectural limitations which make them prone to false positives and false negatives:
- Naive rules create a plague of false positives that are expensive for investigators to sift through
- Sophisticated money launderers know how to circumvent rule-based systems leading to false negatives and potential fines from regulators
This article focuses on the third drawback of existing TMS solutions: how their inflexible data models lead to poor data quality, resulting in additional false positives and false negatives.
I think many of us working in the anti-money laundering (AML) technology space have experienced the frustration of spending many hours retrofitting new data types to squeeze into the rigid data model of a TMS. Unfortunately, the more effort we spend retrofitting data, the more likely we introduce data quality issues. Further, when we don’t complete it in a timely fashion, we’re exposed to risk of large fines from regulators. That said, there’s hope on the horizon from machine learning solutions that are more forgiving of disparate data formats.
Square peg in a round hole
Sending data from source systems to many of the existing TMS is like trying to fit a square peg in a round hole. There are two major reasons for why this is the case.
First, TMS require a lot of data of many various types. Financial institutions typically have many disparate customer, account and transaction systems that feed data into the TMS to satisfy monitoring requirements. Second, existing TMS have a monolithic data model that’s generally difficult to adjust without significant customization.
This forces the financial institution to change its data to conform. However, this is difficult because each source system will have its own unique characteristics and ultimately serve a different business purpose. For example, a mortgage lending application may function differently than a system handling retail demand deposit accounts (DDA). Furthermore, each system will have its own data model or way to store and update information.
Unfortunately, these challenges result in a long, arduous process that’s filled with subtle gotchas, leading to missing potential AML events, leaving you exposed to huge fines from regulators. For example, imagine that a financial institution purchased a commercial loans company. The financial institution must integrate the acquired company’s data into their existing TMS, but the process takes longer than anticipated. During a regulatory exam, the regulator uncovers that the purchased company’s data is still not being monitored by the existing TMS. The regulator views the acquired firm’s lack of integration into the existing AML framework as a red flag and decides to probe the program deeper than it had in the past.
Even worse, the more the data is reshaped to fit the TMS data model, the greater the likelihood of developing additional data issues. And as you know, this will lead to false positives and false negatives down the line.
The best solution is to minimize data transformations. If the files are kept as close to the system’s original format as possible, the data integrity issues will be isolated to the system. While a certain degree of data transformations will be required before the detection algorithms are run, this can be accomplished within the TMS itself. However, this would require a TMS that is not based on a monolithic data model, and has some flexibility and adaptability.
How unsupervised machine learning (UML) leads to a more flexible TMS
There are some promising AI-based TMS solutions that are designed to solve this data inconsistency problem. Using unsupervised machine learning (UML) allows the TMS to have flexible data requirements. (For more information about how UML works in the context of AML, read my first blog post on the subject.)
To understand why, consider their differences. Traditional TMS with rule-based models look for specific scenarios and require specific fields structured in certain ways to map them to their internal data model. UML does not have a strict data model that inputs must adhere to; rather, it works with the data that it’s given.
Consider the scenario where an account was previously dormant and then suddenly began transacting very quickly. A rule would require several highly specific data fields and encode strict thresholds in order to try to match the scenario. However, the rigidity of the data fields make the initial integration difficult which increases the likelihood of data quality issues. A secondary issue is the strict thresholds, which lead to false positives and false negatives.

On the other hand, a TMS that leverages UML can take in a variety of data fields to find hidden networks of accounts with anomalous behavior. For example, UML may uncover a network of accounts that were previously dormant and started transacting quickly.

Note this example is simplified, as in practice the UML model would take into account hundreds to thousands of different data attributes to uncover the network.
There are three major benefits of using UML to power or supplement a TMS. First, with low data integration effort required, there are few chances to make mistakes that lead to data quality issues (and ultimately, false positives and false negatives). Second, it’s faster to get the TMS up and running. And third, it’s much easier to add new data fields or entire new use cases over time. This includes changing business logic (for example, new product offerings are launched) and relentless criminals adapting their methods.
The future of TMS technology
Ultimately, detecting money laundering is extremely complex. To make matters worse, customers, customer behaviors, product offerings, regulatory requirements, and even institutions themselves are under a constant state of change. We must consider that the tools we use to fight financial crime today not only limit our technical capabilities, but may actually influence the way we think about the problem itself. As Marshall McLuhan said, “We shape our tools and afterwards our tools shape us.” It’s time we got some better tools.

The challenges and benefits of mapping SWIFT messages to your Transaction Monitoring System (TMS)
The Regulatory landscape and SWIFT messages
Cross-border payments have been a central theme in recent regulatory actions where regulators levied record breaking fines against financial institutions that failed to comply with Bank Secrecy Act / anti-money laundering (BSA / AML) regulations. The Society for Worldwide Interbank Financial Telecommunications (SWIFT) is, in some sense, at the heart of these violations because it is one of the major facilitators of global money transfers which have come under increased scrutiny.
Editor's Note: This article originally appeared on the Gresham Tech blog on February 18, 2016.
The Regulatory landscape and SWIFT messages
Cross-border payments have been a central theme in recent regulatory actions where regulators levied record breaking fines against financial institutions that failed to comply with Bank Secrecy Act / anti-money laundering (BSA / AML) regulations. The Society for Worldwide Interbank Financial Telecommunications (SWIFT) is, in some sense, at the heart of these violations because it is one of the major facilitators of global money transfers which have come under increased scrutiny.
The enforcement actions came about for a range of reasons, but a general assertion made by regulators in many of the major violations was that banks had inadequate Bank Secrecy Act / anti-money laundering (BSA / AML) programs. A press release issued by the Department of Justice (DOJ) illustrates how regulators perceive failures of anti-money laundering (AML) programs to be a major infraction by financial institutions.
“A four-count felony criminal information was filed today in the District of Columbia charging Commerzbank with knowingly and willfully conspiring to commit violations of IEEPA and Commerz New York with three violations of the BSA for willfully failing to have an effective anti-money laundering (AML) program, willfully failing to conduct due diligence on its foreign correspondent accounts, and willfully failing to file suspicious activity reports. Assuming the bank’s continued compliance with the deferred prosecution agreement, the government has agreed to defer prosecution for a period of three years, after which time, the government would seek to dismiss the charges.”
What does an effective anti-money laundering (AML) program mean?
Effective anti-money laundering programs involve a wide variety of activities, resources, leadership and technology, but for the purpose of this article, the focus will be to discuss what improvements can be made when mapping SWIFT messages to transaction monitoring systems (TMS) and the common pitfalls and data quality issues which arise from this endeavor.
Transaction monitoring systems (TMS) are software applications which have been specifically designed to assist financial institutions to satisfy their BSA / AML requirements by leveraging pattern recognition algorithms that detect activity abnormalities and other money laundering typologies. Financial institutions involved in cross-border payments may be members of SWIFT, and consequently some of the institution’s SWIFT traffic may be subject to BSA / AML monitoring requirements based on their local jurisdiction's rules and regulations.
Mapping SWIFT messages to transaction monitoring systems (TMS)
Data mapping can be a difficult task in itself based on the wide variety of source system applications and middleware a financial institution can be supporting, but some transactional activity is more complex than others to map based on its structure and the number of data elements involved. This is particularly evident when a financial institution maps SWIFT messages to its transaction monitoring system (TMS). Some of the challenges stem from, but are not limited to the following:
- Number of entities involved in the message
- Financial institutions, large corporations, businesses and individuals
- Different SWIFT message types and formats to facilitate various banking functions such as trade finance, foreign exchange, securities settlements, cross border payments, etc.
- Periodic updates and changes to SWIFT message formats and validations
- Free text format of certain fields
- Options to represent the same data differently in the same field
- Large reference data sets required to extract the necessary data for Compliance
- Development of in-house message parsing tools subject to limitations and inaccuracies
- Inflexible vendor solutions that can parse messages, but not to the extent needed for transaction monitoring systems (TMS)
- Knowledge gap between personnel in payment operations and the individuals implementing the transaction monitoring systems (TMS)
Levels of complexity
Financial institutions can vary quite significantly in terms of how sophisticated their monitoring of SWIFT messages is, but all are subject to a certain level of inaccuracy. The table below illustrates three levels of complexity for the mapping of SWIFT messages to a transaction monitoring system (TMS).

Correspondent banks and other financial institutions
Financial institutions which support correspondent banking will be inclined to implement the intermediate and advanced levels of SWIFT message mapping, especially in the more developed countries, because of the amount of scrutiny placed on banks from regulators for engaging in this business. Correspondent banking is considered very risky because the correspondent bank providing clearing services to their respondent banks are predominantly relying on their respondents to have an adequate BSA / AML program. However, respondent banks generally will abide by the rules and regulations of their host country which could differ from the correspondent’s and the perception and risk appetite of each institution can also vary widely.
Financial institutions which do not provide correspondent banking services can still benefit significantly from implementing the intermediate and advanced level of SWIFT data mapping because of the increased detection capabilities the data offers.
Common inaccuracies
If a SWIFT message is not parsed correctly it could misrepresent which role each financial institution played in the message such as the originating bank, sending correspondent, receiving correspondent, beneficiary bank or other type of intermediary.
1. Bank roles and countries in the message flipped
The diagram below represents a MT103 SWIFT message where there are four banks and two customers involved in the message. However, the originating and sending correspondent bank roles have been flipped and the actual sending correspondent bank is represented as the originating bank, and the originating bank appears as the correspondent.

2. Wrong bank and country represented in the message
In the second example in the diagram below, the financial institutions are not flipped, but the originating bank is actually represented incorrectly. The originating bank appears to be located in Mexico, but the bank is actually located in France.

3. Key risk attributes missed in basic mapping model
Another more insidious example that represents the limitations and lack of transparency of mapping SWIFT messages according to the basic level of complexity is shown in the diagram below. First, the originating bank and its country code is unable to be identified because the basic parsing model expects a SWIFT (BIC) to be supplied, but the originating bank’s name and address was populated instead. Second, the basic parsing model is not sophisticated enough to extract the country codes from the originating and beneficiary customer address fields and consequently this key information is blank.
If the mapping model was able to extract the country code from the originating and beneficiary customer address fields, then the Compliance department would have the opportunity to create a new detection scenario such as the customer banking outside of their jurisdiction. While there are instances where an entity can have a legitimate reason to bank outside of its jurisdiction it is an important risk indicator that can be leveraged and help the institution fine tune its system by implementing a more targeted and risk based approach.

Why does accuracy matter?
While on an individual transaction level the inaccuracies described above may appear to be trivial, on a macro scale it could severely undermine a financial institution’s ability to monitor abnormal deviations in its SWIFT message traffic per country, financial institution and customer. Also, inaccurate SWIFT message parsing can have a detrimental effect on a correspondent bank’s ability to detect its respondent banks deviating from their anticipated activity profile which is usually captured when a new bank is on boarded by the correspondent. Deviations in historical activity at the SWIFT (BIC) level could also be an indication that a respondent bank “may” have been de-risked by another correspondent bank and consequently SWIFT traffic needs to be rerouted accordingly.
Another use case for deviations in historical activity is at the country level which could serve as an indication of geopolitical risks. For example, the diagram below represents the aggregation of Mongolian banks SWIFT message traffic over a 17 month period with a significant spike in activity when compared to its historical profile. From January 2013 through April 2014 the average value and volume for Mongolian banks has been $5.6M and 378. However, during the month of May 2015, the value and volume activity totaled $31M and 2,400 respectively. This deviation from the historical profile amounted to a percent change of 472% and 535% as shown in the table below. The spike in activity originating from the Mongolian banks coincided with new sanctions being imposed on Russia by the United States - and Mongolia happens to be in proximity to Russia.
While the above observation doesn’t imply causation, it does provide an interesting statistic for the financial institution’s compliance department to consider investigating. What is driving the sudden increase in SWIFT message traffic from the Mongolian banks and does it pose additional risks which can be mitigated? Conversely, if the spike in activity is innocuous because the financial institution recently expanded its footprint in the region then this explanation can be recorded and documented by the Compliance department to ensure senior management can explain this scenario to internal auditors and possibly regulators which alleviates the risk of the event being construed in a deleterious context.
Mongolian banks value and volume percent change from historical profile
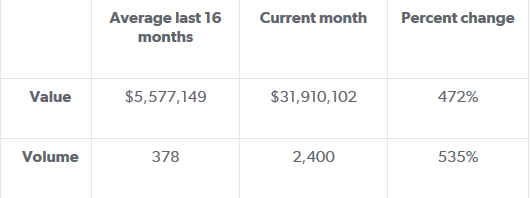
Mongolian banks: SWIFT value & volume historical profile (17 months)

Transparency is the goal
The target state of any financial institution initiating or receiving SWIFT messages should be to have the greatest amount of transparency of their SWIFT traffic based on their risk appetite. Ideally, mapping SWIFT data to a transaction monitoring system (TMS) will allow the financial institution to accurately monitor deviations from historical profiles per country, SWIFT (BIC) and customer. Additionally, extracting country codes from the originating and beneficiary customer's address fields will allow for unique opportunities for custom data analytics and detection models such as customers banking outside of their jurisdiction.
These are some small improvements with low implementation costs which could make a big difference to how risky transactions and correspondent banks can be identified and managed. The question is, why aren't banks already making better use of the SWIFT data they have at their fingertips?