LESSONS LEARNED: RECORD HACKS, BREACHES TO CONTINUE IN 2018 AS MORE CRIMINALS MONETIZE STOLEN DATA
As ACFCS surveys the landscape of what new challenges and opportunities in financial crime 2018 will bring, we are continuing our “Lessons Learned” series, asking key thought leaders what last year taught the community and how that knowledge should help arm compliance professionals for the year ahead.
Not surprisingly, a good predictor of what will happen in 2018 is rooted in trends from 2017, a year where criminals made history with record hack attacks and equally massive data hauls that put millions of people and companies at risk.
Editor Note: This article originally appeared on The Association of Certified Financial Crimes Specialists (ACFCS) website on January 18, 2017.
Written By: Brian Monroe with feedback from Keith Furst
As ACFCS surveys the landscape of what new challenges and opportunities in financial crime 2018 will bring, we are continuing our “Lessons Learned” series, asking key thought leaders what last year taught the community and how that knowledge should help arm compliance professionals for the year ahead.
Not surprisingly, a good predictor of what will happen in 2018 is rooted in trends from 2017, a year where criminals made history with record hack attacks and equally massive data hauls that put millions of people and companies at risk.
These groups – whether large organized criminal outfits, rogue nation state regimes or small-time criminals – didn’t discriminate.
Their targets spanned the spectrum of small and large businesses alike, including banks, law firms, and household name companies, even gaining access to the vast treasure trove of information held by a credit reporting agency.
That likely will only continue this year, and potentially even get worse.
In one word, the sheer magnitude of the data obtained in 2017 was “unprecedented,” said Keith Furst, founder of Data Derivatives, a boutique consulting firm helping institutions with implementing, fine tuning, and validating financial crime systems.
Furst was kind enough to lend his thoughts and insight on these issues and others in a chat with ACFCS Director of Content, Brian Monroe. Here is an edited transcript of that conversation.
What do you think were the biggest financial crime trends in 2017 and why?
One of the biggest financial crime trends of 2017 was the commoditization of sensitive data. While cyberattacks have been increasing in sophistication and frequency for the past few years, the sheer magnitude and quality of the data obtained in 2017 was unprecedented.
For example, the Equifax hack will undoubtedly change the rules of the identification game. In other words, how do I know, you are who you say you are? Simply, possessing the correct data is not enough anymore.
One way to address identification is using knowledge-based authentication (KBA) where questions are asked to the person, which the real person and not the average cybercriminal should know.
Also, it implies that the answers to some of those questions may not be easily accessible in cyberspace. The other emerging trend is biometrics, which could help address some of the identity problem, but could create other issues. For example, if one day, your fingerprints can authorize a money transfer, open your car, and unlock your phone, then what happens when your fingerprints are stolen?
The sad thing about the current state of the world, is that everything is for sale - including sensitive data - and nothing is off limits. There are various marketplaces on the darknet that specialize in the sale of sensitive data, credit card information, child sexual exploitation, hacker-for-hire services, etc.
The fact that data breaches happened with greater frequency and success in 2017 fed the demand as ordinary criminals learned how to monetize these data sources.
For anyone who wants a comprehensive, readable, and non-technical account of cyberwarfare, cybersecurity, and cyberattacks then I highly recommend the book, “Virtual Terror: 21st Century Cyberwarfare,” by Daniel Wagner.
How did the industry respond to those vulnerabilities, regulatory focal points or criminal tactics?
Cybersecurity is a very complex issue because it involves many disparate and amorphous actors, including other nations initiating cyberattacks. Hence, imposing regulations on the private sector can help strengthen protections and controls, but it may not address all of the actors, issues, and challenges in a comprehensive way.
For example, it has been documented that the Chinese government initiates cyberattacks against companies in the United States and steals intellectual property, which is shared with the private and academic sectors to help fuel their economic growth.
So, simply imposing regulatory requirements on private companies that have to protect themselves from an adversary with the financial resources, technical expertise, and determination of a foreign government is not a fair fight.
In other words, cybersecurity is also a topic of foreign policy, and the US government should clearly define parameters of what types of aggression fall into what category and what types of responses are permissible from the private sector.
That being said, there is a lot of value in creating a framework for cybersecurity best practices and the New York Department of Financial Services (NYDFS) was the first US financial services regulator to propose one with its part 500 regulation.
Let’s examine the case of Equifax, to understand what responsibility it bears, a situation where the company got hacked, reportedly, because of a vulnerability identified, but never patched.
Equifax failed to deploy a patch that could have prevented the hack from happening, which means there was an internal governance failure. The other major failure of Equifax was that the company didn’t encrypt the social security numbers of millions of people and left them in a plain text format.
Hence, if a hacker did breach their system, accessing the data was that much easier. However, the one thing that Equifax can’t control is the quality of software available on the market.
Could subjecting institutions to more stringent regulatory rules be unfair, to a certain degree, by not holding the software industry accountable for the products they produce and the cybersecurity standards adhered to?
In summary, it's a good thing that the NYDFS created the part 500 cybersecurity rule, but policy makers must not lose sight of the fact that this is a complex problem with many interrelated actors and penalizing specific agents within the ecosystem could obfuscate the problem.
The financial crime resulting from data breaches also reemphasizes the urgent need for more robust information sharing mechanisms among foreign governments, financial intelligence units (FIU), corporations, and other law enforcement groups.
What else do you think financial crime compliance professionals, regulators and FIs should be doing to better detect and prevent financial crime?
The Clearing house published an excellent paper in February 2017 titled, “A New Paradigm: Redesigning the U.S. AML/CFT Framework to Protect National Security and Aid Law Enforcement,” where they outline some key recommendations.
I don’t agree with all of the recommendations proposed, but a good majority of them make a lot of sense.
The paper discusses information sharing, clarifying regulatory rules, the need for a central repository of beneficial ownership information, regulatory sandboxes, etc. I agree with the paper’s recommendation that regulators should offer institutions the option to participate in regulatory sandboxes under a safe harbor rule that prevents penalties if something goes wrong.
US regulators seem to be worried that allowing sandboxes will give institutions the opportunity to wiggle their way out of responsibility.
The reality is that identifying money laundering and other types of financial crime is very complex and using more advanced technology, such as the machine learning, natural language processing (NLP), and computer vision, can aid in that process.
Many enforcement actions reference governance as one of the main causes to serious compliance failures. But why are compliance programs so hard to govern effectively? Well, because they are complex systems, and managing complexity is not easy. This leads to another question of whether new technology can help reduce complexity and make governance easier.
Artificial intelligence (AI) and regulatory technology (regtech) are full of hype right now and sometimes it's hard to parse out the prize from the promise. However, institutions should be cautiously optimistic, as am I, and should start by focusing on innovation with small use cases regardless of the regulatory environment they are in.
There have been some incredible advances and achievements of AI-embedded technology, so institutions need to start experimenting now so they don’t fall behind.
Also, big data platforms can help address one of the major issues plaguing financial crime programs for years, which is data integrity. In these central repositories, institutions can manage the enterprise meaning of their data and not only its movement.
What is an example you have seen using these technologies?
There was an AI vendor which helped a leading global financial institution reduce false positive alerts by 20% from its transaction monitoring system (TMS). This is an important step in the right direction because it frees up capital to invest in other areas of a compliance program, such as risk assessments, model risk management, quality assurance, etc.
What do you think will be the big issues to tackle in 2018?
There will probably be a spike in new corporation registrations, including shell companies, as Trump’s new tax plan, Tax Cuts and Jobs Act or TCJA, incentivizes people to open corporations as vehicles to hold assets, shield income, pay dividends, etc.
It’s ironic that on one hand, US policymakers are pushing for more transparency on the beneficial owners of legal entities as proposed by the TITLE Act and Corporate Transparency Act, but on the other hand, pass a law that will likely increase the number of legal entities designed to play tax games.
This actually creates more work for financial institutions because they will have to conduct more due diligence on opaque legal entities. Financial institutions should plan on using automated solutions and robust reference data to deal with the increasingly complex and burdensome problem of beneficial ownership.
Lastly, do you have any tips to help banks maximize resources and better keep their teams strong in a time of tight budgets?
A colleague of mine once told me that some banks don’t have time to look at new technology because they are too busy managing their current program. Well, this is exactly the reason why innovation needs to be a top priority for compliance teams in 2018.
The regulatory requirements and the nature of the problem continue to increase in complexity, so doing things the same way is not sustainable.
While some regulatory regimes have embraced the notion of a regulatory sandbox, this should not prevent institutions operating within other jurisdictions from experimenting. This doesn’t mean that anything needs to get deployed into production, but what it does mean is there should be activity and proof of concepts (POCs) happening in the background.

Data reusability: The next step in the evolution of analytics
Data reusability will lessen the response time to emerging opportunities and risks, allowing organisations to remain competitive in the digital economies of the future.
- If data's meaning can be defined across an enterprise, the insights that can be derived from it expand exponentially
- When financial institutions work together to identify useful data analytics solutions they can produce great results and add a lot of value to their customers
- The analytic systems of tomorrow should be able to take the same data set and process them without modifying them
Data reusability: The next step in the evolution of analytics 2017-07-25T16:36:19+00:00
Editor's Note: This article originally appeared on The Asian Banker on July 20, 2017.
By Keith Furst and Daniel Wagner
Data reusability will lessen the response time to emerging opportunities and risks, allowing organisations to remain competitive in the digital economies of the future.
- If data's meaning can be defined across an enterprise, the insights that can be derived from it expand exponentially
- When financial institutions work together to identify useful data analytics solutions they can produce great results and add a lot of value to their customers
- The analytic systems of tomorrow should be able to take the same data set and process them without modifying them
If data is the new oil, then many of the analytical tools being used to value data require their own specific grade of gasoline, akin to needing to drive to a particular gas station with a specific grade of gasoline with only one such gas station within a 500-mile radius. It sounds completely ridiculous and unsustainable, but that is how many analytical tools are set up today.
Many organisations have data sets that can be used with a myriad of analytical tools. Financial institutions, for example, can use their customer data as an input to determine client profitability, credit risk, anti-money laundering compliance, or fraud risk. However, the current paradigm for many analytical tools requires that the data to be used must conform to a specific model in order to work. That is often like trying to fit a square peg in a round hole, and there are operational costs associated with maintaining each custom-built tunnel of information.
The advent of big data has opened up a whole host of possibilities in the analytics space. By distributing workloads across a network of computers, complex computations can be performed on numerous data at a very fast pace. For information-rich and regulatory-burdened organisations such as financial institutions, this has value, but it doesn’t address the wasteful costs associated with inflexible analytic systems.
What are data lakes?
The "data lake" can provide a wide array of benefits for organisations, but the data that flows into the lake should ideally go through a rigorous data integrity process to ensure that the insights produced can be trusted. The data lake is where the conversation about data analytics can shift from what it really ought to be.
Data lakes are supposed to centralise all the core data of the enterprise, but if each data set is replicated and slightly modified for each risk system that consumes it, then the data lake’s overall value to the organisation becomes diminished. The analytic systems of tomorrow should be able to take the same data set and process them without modifying them. If any data modifications are required it could be handled within the risk system itself.
That would require robust new computing standards, but at the end of the day, a date is still a date. Ultimately, it doesn’t matter what date format convention is being followed because it represents the same concept. While there may be a need to convert data to a local date-time in a global organisation, some risk systems enforce date format standards which may not align with the original data set. This is just one example of pushing the responsibility of data maintenance on the client as opposed to handling a robust array of data formats seamlessly in-house.
The conversation needs to shift to what data actually means, and how it can be valued. If data’s meaning can be defined across the enterprise, the insights that can be derived from it expand exponentially. The current paradigm of the data model in the analytics space pushes the maintenance costs onto the organisations which use the tools, often impeding new product deployment. With each proposed change to an operational system, risk management systems end up adjusting their own data plumbing in order to ensure that they don’t have any gaps in coverage.
Data analytics solutions add value
When financial institutions work together to identify useful data analytics solutions they can produce great results and add a lot of value to their customers. The launch of Zelle is a perfect example, since customers from different banks can now send near real-time payments directly to one another using a mobile app.
A similar strategy should be used to nudge the software analytics industry in the right direction. If major financial institutions banded together with economies of scale to create a big data consortium where one of the key objectives was to make data reusable, then the software industry would undoubtedly create new products to accommodate it, and data maintenance costs would eventually go down. Ongoing maintenance costs would eventually migrate from financial institutions to the software industry, which has the operational and cost advantages.
There are naturally costs associated with managing risk effectively, but wasteful spending on inflexible data models takes money away from other things and stymies innovation. US regulators are notoriously aggressive when it comes to non-compliance, so reducing costs in one area could encourage investment into other areas, and ultimately strengthen the risk management ecosphere. Making data reusable and keeping its natural format would also increase data integrity and quality, and improve risk quantification based on a given model’s approximation of reality.
Reusable data will allow institutions to have a "first mover advantage"
Is the concept of reusable data too far ahead of its time? Not for those who use it, need it, and pay for it. Clearly, the institution(s) that embrace the concept will have the first mover advantage, and given the speed with which disruptive innovations are proceeding, it would appear that this is an idea whose time has come. As the world moves more towards automation and digitisation it is becoming increasingly clear that the sheer diversity and sophistication of risks makes streamlining processes and costs a daunting organisational task.
The speed at which organisations must react to risks in order to remain competitive, cost-efficient and compliant is decreasing, while response times are increasing, right along with a plethora of inefficiencies. Being in a position to recycle data for risk and analytics systems would decrease response times and enhance overall competitiveness. Both will no doubt prove to be essential components of successful organisations in the digital economies of the future.
Keith Furst is founder and financial crimes technology expert of Data Derivatives; and Daniel Wagner is managing director of Risk Cooperative.

Data integrity can no longer be neglected in anti-money laundering (AML) programs
The New York State Department of Financial Services (NYDFS) risk based banking rule, went into effect on January 1, 2017 and will have a significant impact on the validation of financial institutions’ transaction monitoring and sanctions filtering systems. The final rule requires regulated institutions to annually certify that they have taken the necessary steps to ensure compliance.
Data integrity is particularly interesting because it arguably hasn’t been given the same emphasis as other components of an effective anti-money laundering (AML) program, such as a risk assessment.
There has always been an interesting dynamic between the way compliance and technology departments interact with one another. This new rule will force institutions to trace the end-to-end flow of data into their compliance monitoring systems which could be a painful exercise. This exercise will demand the interaction between groups which may have stayed isolated in the past and it will require some parts of the organization to ask tough and uncomfortable questions to others. Clearly, gaps will be found and remediation projects will have to be launched to address those items.
Editor's Note: This article originally appeared on the Gresham Tech blog on May 15, 2017.
The New York State Department of Financial Services (NYDFS) risk based banking rule, went into effect on January 1, 2017 and will have a significant impact on the validation of financial institutions’ transaction monitoring and sanctions filtering systems. The final rule requires regulated institutions to annually certify that they have taken the necessary steps to ensure compliance.
Data integrity is particularly interesting because it arguably hasn’t been given the same emphasis as other components of an effective anti-money laundering (AML) program, such as a risk assessment.
There has always been an interesting dynamic between the way compliance and technology departments interact with one another. This new rule will force institutions to trace the end-to-end flow of data into their compliance monitoring systems which could be a painful exercise. This exercise will demand the interaction between groups which may have stayed isolated in the past and it will require some parts of the organization to ask tough and uncomfortable questions to others. Clearly, gaps will be found and remediation projects will have to be launched to address those items.
But does data integrity need to be such a painful endeavor? Could there be a better way to streamline the process - and even create value to the institution as a whole - increasing the enterprise value of data (EvD) by ensuring its integrity?
Can New York regulators really have a global impact?
Any financial institution which is regulated by the NYDFS should have already reviewed this rule in detail. Some have even suggested if financial institutions haven’t launched projects to ensure they can certify by April 15, 2018, then they are already behind.
What about financial institutions with no physical presence in the United States? Should these banks be paying close attention to this regulation? The answer is unequivocally – yes. First of all, if you read the rule it’s straight to the point and makes a lot of sense (it’s only five pages long). But it goes beyond just common sense and raising the standards and accountability for AML programs.
Imogen Nash, of Accuity, explored the global implications of NYDFS regulations, in a blog post back in August 2016, which are succinctly summarized below:
Ultimately, the argument is that as long as the U.S. dollar continues to hold its dominance among the world’s currencies then the reverberations of what the NYDFS requires will be felt across the globe.
What is data integrity?
Data integrity can be described as the accuracy and consistency of data throughout its entire lifecycle of being used by business or technical processes. The importance of accurate data in a financial institution can be easily demonstrated with a simple mortgage use case.
On day one, a customer is approved for a $1,000,000 mortgage with a monthly payment of $5,000. Let’s imagine that the loan system which approved that mortgage had a “bug” in it and on day thirty, the outstanding loan balance suddenly went to $0. Obviously, maintaining an accurate balance of outstanding loans is an important data integrity task for financial institutions.
Do banks really make these types of errors?
It wouldn’t be the norm, but there have been documented cases of unusual bank glitches, such as the Melbourne man whose account was mistakenly credited $123,456,789.

The miraculous $123M credit to a customer’s account is definitely an outlier because most core banking systems function fairly well. However, the reliability of a core banking system can’t necessarily be correlated to transaction monitoring and sanction screening systems.
The fundamental difference between the two types of systems is that the latter need to aggregate data from many different banking applications which are in scope for compliance monitoring. While each core banking application may function reliably well on its own - when all of these disparate banking systems are aggregated together into one compliance monitoring system, then various data integrity and quality issues arise.
But it’s not only the aggregation of disparate systems which is a problem, it’s the fact of how these systems are aggregated, which is like “fitting a square peg into a round hole.” Banks systems come in many shapes and sizes, but compliance monitoring systems are one-size-fits-all. Just imagine Shaquille O'Neal trying to fit into a toddler’s sneakers and then playing a full court basketball game. Some things just don’t fit and when things don’t fit, it could impact performance. It’s the same idea when forcing data into compliance monitoring systems.
Why the extract, transform and load (ETL) process is a serious risk for compliance?
The process of moving data from the core banking applications to the transaction monitoring and sanctions screening systems presents several challenges and risks which should be validated on an ongoing basis. The process which moves data from one source system to another is generally referred to as the extract, transform and load (ETL) process. There are questions which arise at each stage of the ETL process such as:
- Was all of the data extracted properly?
- Was all of the data transformed from the source to the target system as designed?
- Was all of the data loaded from the source to the target system successfully?
Unless the a financial institution’s information technology (IT) department has already implemented data integrity and quality reports for their compliance partners, then the ETL process which supports financial crimes is nothing more than a “black box.” In other words, there would be no reliable way to determine the effectiveness of the data migration processes and controls without some level of reporting outside of IT.
Does the below interaction sound familiar?

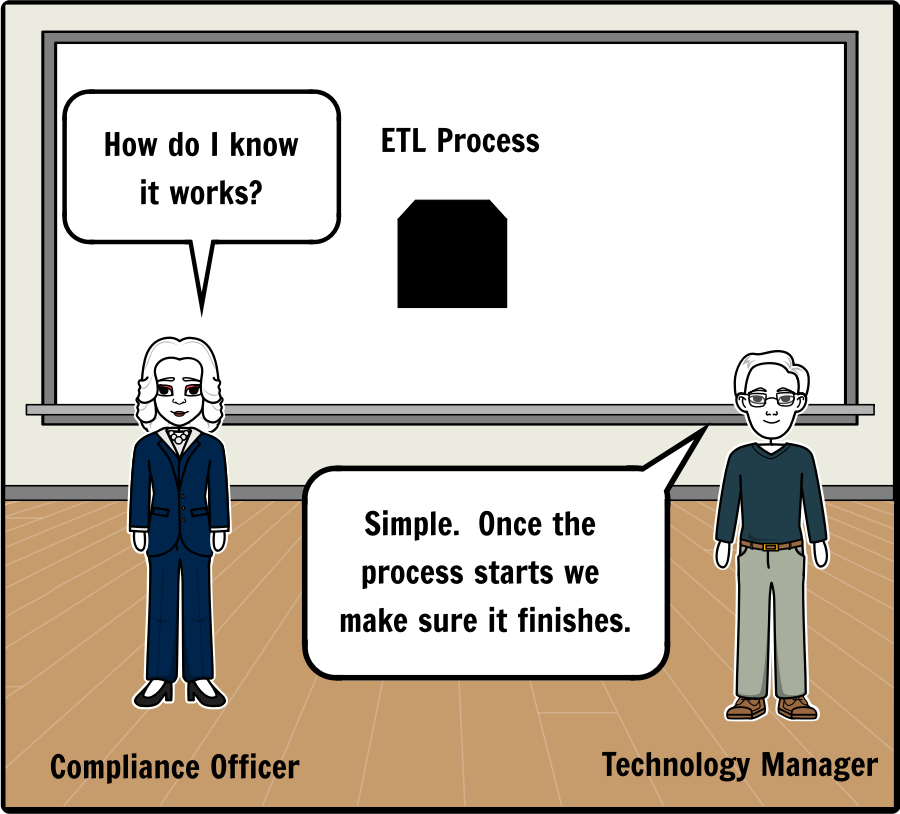

The screenshot below highlights two requirements in the NYSDFS rule, but the key word to notice is “validation.” To validate the integrity, accuracy and quality of data is actually a significant effort because validation not only implies that a process is taking place, but it’s safe to assume that evidence will be requested to prove that the validation itself was complete and accurate. Since the rule is requiring the Board of Directors or Senior Officer(s) to certify that their institution is complying, then clearly senior management should require reporting around the ETL process or “black box” which feeds data into the transaction monitoring and sanctions screening systems.
2. validation of the integrity, accuracy and quality of data to ensure that accurate and complete data flows through the Transaction Monitoring and Filtering Program;
3. data extraction and loading processes to ensure a complete and accurate transfer of data from its source to automated monitoring and filtering systems, if automated systems are used;
Source: http://www.dfs.ny.gov/legal/regulations/adoptions/dfsp504t.pdf
It’s just data. No big deal right?
Implementing data integrity and quality checks is no simple feat and transaction monitoring and sanctions screening systems will have their own unique requirements. Transaction monitoring systems (TMS) generally require some level of transformation logic which categorizes various transaction types into groups, which are monitored by different AML models.
There are other common transformations which occur to support the TMS, such as converting foreign currencies to a base currency used for calculation logic. Obviously, you can’t sum transactions completed in Euros (€) and Japanese Yen (¥) together because the result would be erroneous.
These transformation rules are also susceptible to data integrity issues if the source systems make changes to their application without informing the owners of the TMS, who also may need to make changes to their own processes.
Why data integrity projects have failed in the past
Data integrity is not a new concept for those who work with AML systems. Actually, data integrity issues could potentially rank as one of the more popular responses by industry professionals for major impediments to the effectiveness of AML systems. Some banks are still using the data integrity processes they built internally or with third parties with varying degrees of success and sustainability.
One of the main issues is that many of these data integrity processes are built within the databases themselves or a dedicated data warehouse is constructed for this end. This may seem like a minor detail, but there are four ramifications:
- Exclusions: If, any exclusions are applied to customer, account or transaction data then it could be difficult to monitor what data is in scope and if it was extracted properly.
- Square peg in a round hole: The transform process is susceptible to significant data integrity issues because the source system is forced to conform to the compliance monitoring system’s data structure.
- Data validation: Generally, if a financial institution does have any data validation processes then they will performed in the “staging area” of the compliance monitoring system to ensure basic data integrity. Once the data validation process is moved forward to the “staging area”, then it’s essentially skipping steps one and two in the ETL process which can contribute to data integrity issues that are not identified. Another question which arises about the process is whether it’s ongoing or was performed one-time.
- Data lineage: When financial institutions use inflexible monitoring systems with strict data models it presents a challenge to data lineage. How can the financial institution trace back the data in the monitoring system to what’s in the source system? Even if they could follow the breadcrumbs; did the transform step in the ETL process manipulate the data so extensively that it’s become unrecognizable?

A path forward under the spotlight
Data integrity doesn’t seem to be going away anytime soon based on the fact that the NYDFS has just shined the spotlight on this issue. In our highly fragmented and compartmentalized modern world we may need to see the challenges we face through a new and objective lens.
Traditional approaches to data integrity projects have yielded limited quantifiable results in the past. Isn’t it about time to try a more flexible solution which can evolve seamlessly with the institution’s regulatory requirements and technological landscape?
Cost, flexibility and speed are three components of monitoring systems that financial institutions must manage effectively as regulatory requirements continue to expand due to growing threats such as cybersecurity. Data integrity is much broader than just compliance, but building the foundation to get it right for compliance monitoring can cross pollinate into other areas of the enterprise. Ultimately, data integrity can become a strategic business advantage when trying to enter new markets and launch new products.
[1] Onaran, Yalman. “Dollar Dominance Intact as U.S. Fines on Banks Raise Ire.” Bloomberg. 16 July 2014. http://www.bloomberg.com/news/articles/2014-07-15/dollar-dominance-intact-as-u-s-fines-on-banks-raise-ire
Web. 13 July 2016.